You can check the first article of this series: Big Data: Get the data
After having the data, next step is to have a Hadoop cluster or single machine installation to “upload” the data and run the processes.
Even that Hadoop is meant to run on lots and lots of machines at the same time, we can make a single virtual machine installation to run tests and start hacking with it.
If the purpose of your Hadoop learning is just for programming and not be a full system administrator, this is a good way to start.
Pros
- There is no need to buy and build several machines
- All inside your own machine
- Running in minutes
Cons
- Slower than a real cluster
- Just for testing purposes
Create the Virtual Machine
The company Hortonworks provides the Hortonworks Sandbox, a Virtual Machine image with a full Hadoop environment. It saves us the time and pain of installing and configuring the machine.
It comes out of the box with Hadoop, HBase, ZooKeeper, Hive, etc. Just take a look at the sandbox page to see all the details.
Step 1: Install VirtalBox 4.2+ Step 2: Download the Sandbox 2 for Virtualbox (2.5 GB) Step 3: Install the .ova image downloaded on VirtualBox and follow the instructions. Step 4: Run!!!
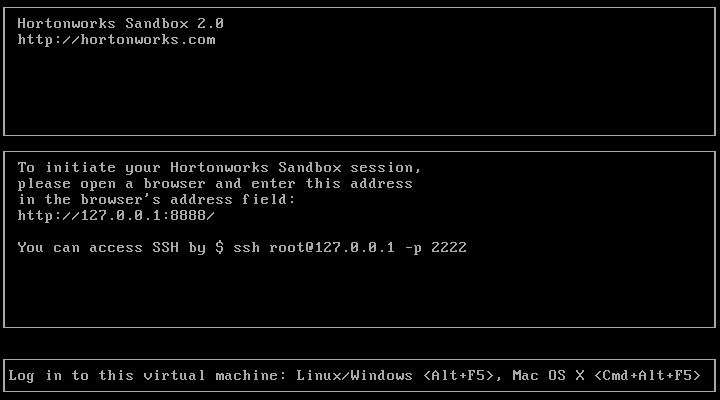
Just wait to full start of the machine and you will get a screen with the instructions. It lets you:
- Enter the web interface on http://127.0.0.1:8888/ (Asks for registration). It gives you tutorials and tool preferences.
- SSH the server with ssh root@127.0.0.1 -p 2222, the password is “hadoop”.
- Change to another console inside the virtual machine with Alt+F5
Start hacking with Hadoop
For testing that it works, let’s run a little test using Hadoop.
Upload data to HDFS
To allow access to the data into Hadoop environment, we use HDFS (Hadoop Distributed File System). It holds and manages the files and allows access to the processes. In a multi-server environment, HDFS would replicate and share data between several machines.
Note: Some command are run from the client and other are run inside the VM.
The user to log and access by ssh is hue, the default user for the web interface.
Create the ‘boe’ folder: this folder will hold the input data to our job.
ssh hue@127.0.0.1 -p 2222 "hdfs dfs -mkdir boe"
Upload BOE-A-2013-1 file to boe/BOE-A-2013-1 file on HDFS. The cat command avoids to upload the file to the VM and then to the HDFS.
cat BOE-A-2013-1 | ssh hue@127.0.0.1 -p 2222 "hdfs dfs -put - boe/BOE-A-2013-1"
It is possible to check the results on the web interface http://127.0.0.1:8000/filebrowser/
Run a test map/reduce job
Log on the VM and download the wordcount.jar, it contains the java classes to run the job.
ssh hue@127.0.0.1 -p 2222
[hue@sandbox ~]$ wget https://github.com/jmaister/wordcount/blob/master/wordcount.jar?raw=true
Execute the JAR with hadoop.
[hue@sandbox ~]$ hadoop jar wordcount.jar com.jordiburgos.WordCount boe wordcountout
...
... INFO mapreduce.Job: The url to track the job: ...:8088/proxy/application_1386615892390_0013/
... INFO mapreduce.Job: Running job: job_1386615892390_0013
... INFO mapreduce.Job: Job job_1386615892390_0013 running in uber mode : false
... INFO mapreduce.Job: map 0% reduce 0%
... INFO mapreduce.Job: map 100% reduce 0%
... INFO mapreduce.Job: map 100% reduce 100%
... INFO mapreduce.Job: Job job_1386615892390_0013 completed successfully
... INFO mapreduce.Job: Counters: 43
File System Counters...
Job Counters...
Map-Reduce Framework...
Now that the job has ended, the results are available con the wordcountout HFDS folder. There are two options to see the results. http://127.0.0.1:8000/filebrowser/ or using and HDFS command:
[hue@sandbox ~]$ hdfs dfs -cat "wordcountout/part-r-00000"
CONFORMIDAD 1
ESS/1/2012, 4
ESS/2825/2012, 1
El 1
Empleo 4
Laboral 1
Ley 3
Ministerio 2
Ministra 1
Oficial 2
Orden 5
Seguridad 4
Social 1
...
The result is a file with the words and the number of occurrences. Quite easy and fast with any programming language, but this is juast a test.
Conclusion
The single node hadoop is now up and running and we can send jobs to be executed.
On next articles of the series, a better example of a MapReduce implementation will be done. To read and process all the XML files from the first article: Big Data: Get the data.
Also, there will be room for another article how to automatically build the JAR for running the Hadoop job.
